对于想让在线销售大户的那些人-营销人员和网站所有者,您是否知道,要使其升至搜索引擎结果页的顶部,就需要您拥有独特而翔实的内容,而不是重复的内容?是的,毕竟内容为准。让我们进一步了解什么是重复内容以及为什么重要。
不接受SEO中的重复内容。
搜索引擎有一个问题,在SEO中被称为“重复内容”。
什么是重复内容?
重复内容是显示在网络上多个URL或位置上的内容。
因此,搜索引擎通常将不知道应显示哪个内容页面,哪些不应该出现在搜索结果中。
这将严重损害网页的排名。
因此,重复内容和SEO成正比。
当搜索用户开始链接到给定Web内容的每个不同版本时,该问题会进一步恶化,从而使问题更加严重。
在此博客中,我们努力回答了什么是重复内容,什么被视为重复内容等。
让我们立即开始工作。
SEO中的重复内容是什么?
Google在SEO中重复的内容不过是出现在Internet上某个位置的内容。
该特定的“一个地方”被称为具有唯一网址或URL的位置。
因此,同一条内容出现在多个网址中,然后在SEO中将其称为重复内容。
尽管从技术上看,这似乎是一种惩罚,但SEO中重复的内容有可能极大地影响您的搜索引擎排名。
此外,正如Google所指,还有一种称为“近似相似”的内容,这些内容出现在Internet的多个位置。
这使搜索引擎极难选择哪个版本与任何给定的搜索查询最相关。
希望这回答了问题–什么是重复的。
重复的内容和SEO –为什么重复的内容很重要?
什么是重复内容后出现的下一个问题是重复内容是否损害SEO?
好吧,非常重要!Google重复内容惩罚就是证明。
Google对重复内容和重复帖子的处罚。
因此,如果您想避免Google重复内容的罚款,就必须摆脱网站上的重复内容。
现在,重复的内容对搜索引擎和网站所有者都构成了重大威胁。
让我们详细了解这些问题。
对网站所有者的威胁
什么是重复内容?现在,让我们继续讨论由此带来的威胁。
不同网站上的重复内容将使网站所有者和营销人员遭受排名以及流量损失。
这些问题通常源于两个主要问题:
- 搜索引擎在努力提供最佳搜索结果的过程中绝不会显示某一特定内容的多个版本。
因此,他们被迫在最有可能成为理想结果的版本之间做出选择。这极大地稀释了每个重复项的总体可见性。 - 接下来,链接资产将被进一步稀释,因为其他各个站点也应在这些重复内容之间进行选择。
在这里,所有入站链接而不是指出单个内容,而是链接回多个内容,甚至在重复项之间分散链接资产。
由于入站链接是重要的排名因素,因此无疑会影响给定内容的搜索可见性。

搜索引擎的威胁
对于搜索引擎,重复的内容可能会带来三大威胁,即:
1.他们不会知道应该从索引中排除还是包含哪个版本
2.他们不知道是否应该将链接度量标准(例如链接资产,权限,锚文本,信任等)定向到一个特定页面,还是只是将其分开在不同版本之间
3.在回答查询结果时,他们也不确定要对哪个版本进行排名
那么,最终结果将是什么?好吧,这将是一条内容,不会获得任何本来可以获取的搜索可见性。
重复内容的问题如何出现?
在大多数情况下,营销人员和网站所有者并非故意创建重复的内容。
但是,这当然并不意味着它不存在。
此外,一些估算表明,将近29%的Web实际上包含重复内容。
尽管我们了解大多数情况下并非故意创建重复内容,但以下是一些常见的创建方式:
1. URL的变体
通常,某些特定的URL代码(例如某些分析代码和跟踪)会导致重复的内容问题。
这不仅是由参数引起的问题,还可能与这些参数的顺序有关,这就是它们在URL中出现的方式。
例如,让我们考虑以下URL结构:
- gadgets.com/green-widgets?color=green&cat=4将是www.gadgets.com/green-widgets?cat=4&color=green的副本
- gadgets.com/green-widgets?color=green将是www.gadgets.com/green-widgets的副本
通常会创建重复内容的另一个因素是“会话ID”。
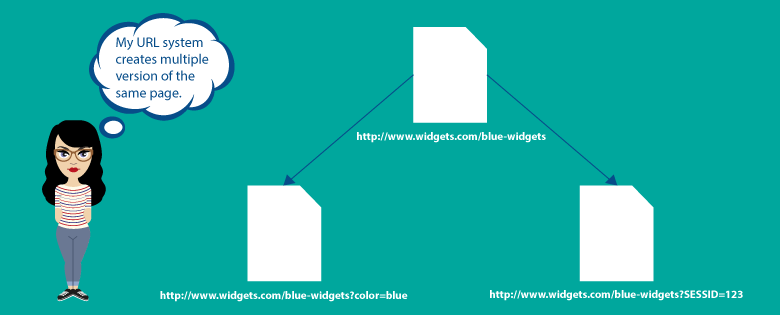
这主要是在为每个访问特定网站的用户分配一个唯一的会话ID,然后将其存储在URL中时发生的。
另外,内容的打印机友好版本也将导致重复的内容问题,特别是当给定页面的不同版本被索引时。

因此,在这一点上要记住的一点是,只要有可能,放弃添加任何备用URL版本或更多URL参数的过程将非常有益。
这是因为其中包含的信息通常会通过脚本传递。
2.非WWW与WWW或HTTPS与HTTP页面
如果您的网站在“ site.com”和“ www.site.com”上包含不同的版本(带有和不带有前缀“ www”),那么同样的内容也可以应用于这些网站–这两个版本–这仅表示您已经创建了这两个页面的副本。
这也适用于在https://和http://上维护其版本的网站。因此,当特定页面的两个版本都处于活动状态并且对搜索引擎也可见时,那么您很可能会遇到重复内容的问题。
3.复制或报废的内容
当我们说内容时,它不仅包括社论内容或博客文章,还包括有关产品信息的页面。
在其网站上重新发布已经发布的博客内容的爬虫将很明显是重复内容的来源。
但是,电子商务网站也面临一个问题-相同的产品信息。
如果多个网站销售特定产品或相同商品,则所有这些网站最终将使用相同制造商对这些商品的描述。
这样,相同的内容将最终出现在网络上的不同位置。
如何解决重复内容的问题?
现在,解决Google SEO重复内容的问题可以归结为一个中心思想,也可以使用重复内容工具来完成。
在这里,中心思想是指定这些重复项中的哪一个是“正确的”。
每当在Internet上的不同位置找到网站内容时,都应始终对搜索引擎进行规范化。
现在,让我们研究实现这一目标的三种主要方法。这些包括:
- 利用 301重定向 以获取正确的URL
- 转到属性rel = canonical
- 利用Google Search Console的参数处理工具
1.利用301重定向
在大多数情况下,一种理想的方法是解决重复内容的问题,那就是建立301从“重复”页面到原始页面的重定向。
当几页具有良好排名潜力的页面合并到一页时,它们将完全停止彼此竞争,并且还将在各处形成更强的人气和相关性信号。
这将对“实际” /“原始”页面的良好排名产生积极影响。

2.转到属性Rel =“ Canonical”
处理重复项的下一个选择是利用rel = canonical。
这将指导搜索引擎认为应该将特定页面视为已指定URL的副本。

而且,它告诉您内容指标,所有链接以及搜索引擎应用于此网页的“排名能力”实际上应该提供给指定的URL。
Rel = canonical属性是网页HTML头的一部分:
<头>
(不同的代码可能在文档的HTML头中)
<link href =“原始网页的网址” rel =“ canonical” />
(不同的代码可能在文档的HTML头中)
</ head>
然后,应将此属性添加到重复页面的HTML头的每个版本中。
这应该与上面讨论的“实际页面的URL”部分一起完成,应该用指向实际(规范)页面的链接代替。
确保保留引号。
该属性大致提供与301重定向相同的排名能力或链接资产。
但是,由于它是在网页级别而不是服务器级别实现的,因此开发和实现所需的时间通常很少。
3. Noindex元机器人
一个 meta标签 是处理与重复的内容相关联的问题,特别有用的是元机器人。
当使用“ nofollow,index”之类的值时。尽管从技术上讲,这称为content =“ noindex,follow”,但通常称为Meta Noindex,Follow。
您可以轻松地将meta robots标记添加到每个页面的HTML标题中,这些页面必须保持在搜索引擎的索引范围之外。
现在,此meta robots标签使搜索引擎能够启用网页上的链接,但阻止它们将这些链接添加到索引中。
尽管您不希望搜索引擎对其进行索引,但也必须对这个重复项进行爬网。
这是因为Google强烈警告不要将其抓取访问限制为网站上存在的重复内容。
搜索引擎始终喜欢被代码中可能出现的所有错误所访问。
这主要是因为它帮助他们在其他模棱两可的情况下做出决定。
利用元机器人可以特别有效地解决与分页有关的重复内容相关的问题。
在Google Search Console中处理参数和首选域
使用Google搜索控制台,营销人员和网站所有者可以为其网站设置首选域名。
它还可以帮助您弄清楚Googlebot是否应以不同方式抓取不同的URL参数。
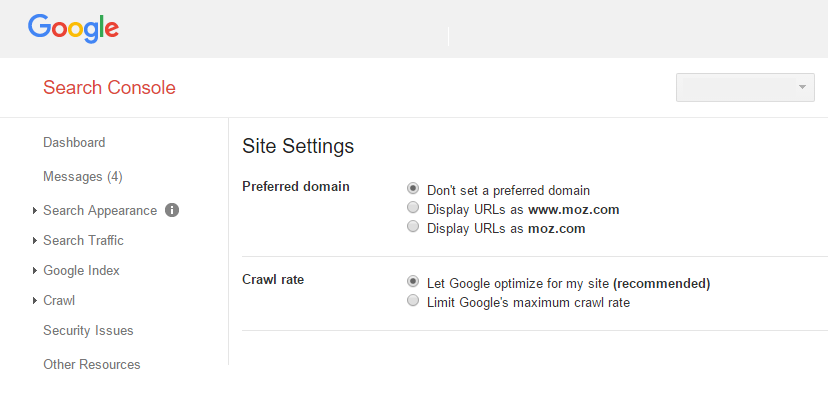
根据与重复内容和URL结构相关的问题的实际原因,您可能会找到一种解决方案,设置参数保存或首选域,或同时设置两者。
当您选择参数保留作为解决重复内容问题的选项时,可能会出现问题-您所做的修改仅适用于Google。
基本上,使用Google搜索控制台实施的任何计划当然都不会影响Bing 或Google以外的任何其他搜索引擎的爬 网程序对您的网站的解释方式。
因此,对于其他搜索引擎,您可以利用网站管理员工具以及对Google Search Console设置的调整。
处理重复内容的额外措施
以下是一些解决重复内容造成的问题的技巧:
- 在整个网站上进行内部链接时,在内部链接期间保持一致性至关重要。
- 联合内容只是确保要联合的网站提供指向实际内容的链接,而不是URL的变体。
- 要特别小心那些试图窃取您的SEO积分的内容抓取者,否则它们会通过将rel = canonical链接(自引用)添加到现有网页来窃取您的Web内容
这样,您可以保护您的原始内容并保持在SERP之上。
--- END ---